-->
Chandra Source Catalog: Onto the Google Sky (Part 1)
From time to time in the Chandra blog, we like to give a look at the behind the scenes of how things really work around here. As you may suspect, it takes a lot of effort from many, many people to make this mission a success. One area we haven't delved into too much yet is the "data analysis" and other herculean efforts that are required to make the Chandra data as useful and user-friendly as possible to the scientific community.
Ken Glotfelty works in this important endeavor and has written this blog entry on how the Chandra Source Catalog - the definitive list of what the Chandra has observed over its lifetime - has made its way into Google Sky. Since there's a lot of ground to cover, we'll split this entry into two parts. This week, we begin with part one.
The science data from the ACIS and HRC instruments on Chandra are processed through a series software modules, or pipelines, that do things like
- convert spacecraft values to physical units (for example, the conversion from the location on the detector to celestial coordinates)
- flag and remove detector anomalies such as bad pixels
- identify good times during the observation when all the spacecraft systems, such as the transmission gratings, have been moved into/out-of place.
Once this "Standard Data Processing" is complete and the data have been validated, they are made available to the scientists who requested the observation to perform whatever specific science analysis their research entails. In Standard Data Processing, the processing is focused on the observation as a whole, not on individual sources within that observation.
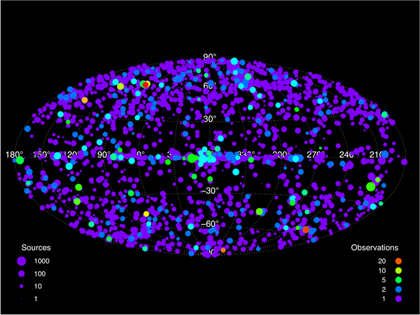
The Chandra Source Catalog (CSC) project takes the next step and aims to process data on a per-source basis. Since Chandra may observe the same source multiple times in different observations, these multiple observations of the same source need to be merged so that its properties are only reported once -- while still maintaining all the per-observation information. Since some observations are long and some are short, some use the ACIS instrument and others use the HRC instrument, and since some of the observations may be taken years apart or optimized for different science objectives, this merging process is very tricky. Data in the Chandra Source Catalog are all processed uniformly to provide users with as unbiased as possible sample of X-ray sources that have been observed with Chandra.
In total there are over 700 quantities that computed for each of the roughly 100,000 sources in the current catalog release that is built from about 4000 individual ACIS observations that were completed during the first eight years of the mission. Soon another year’s worth of data will be processed and data from the HRC will also be included.
The CSC goes far beyond just a position and some measure of the brightness (or flux); i.e. record information about any variability seen in the source (using several different tests), a set of X-ray "colors" or (hardness ratios), and many more. Most values are reported in multiple energy bands and estimates of the uncertainty are provided (usually with upper and lower limits).
These data and the associated files used to create them will allow unprecedented access to Chandra data. A typical X-ray astronomer will be able to quickly use the tabular data to sift through the sources and identify classes of objects -- or more interesting -- those sources that don't fit into any standard classification. The file-based products allow users the option to start their analysis without having to worry about many of the low-level details that Chandra users must be aware of.
Maybe even more importantly, these data will be directly usable by astronomers who are not experts in X-ray astronomy. X-ray data processing is very different from other wavelengths and Chandra is no exception. There is a significant learning curve to understand all the analysis tools and to work through all the analysis threads just to produce a single flux estimate (with errors) for a single source in a single observation. With the CSC, it will now be easy to add Chandra data as another data-point in multi-wavelength research project.
It should not be surprising then that the Chandra Source Catalog project took considerable time to design the science algorithms and to develop, test, and optimize the software as well the necessary computer hardware to run it on. After the data were processed, they went through a "Quality Assurance" phase where we did identify and correct a few software bugs and unexpected corner cases where the science algorithms performed inappropriately.
In the next installation, I'll talk about taking the CSC out of its usual venues and into Google Sky.
-Ken Glotfelty, CXC
Category:
- Log in to post comments